
- Research Statement
- Theoretical Research
- Background Modelling and Foreground Detection
- Occlusion Detection in Image Segmentation
- Preprocessing Filters for Vehicle Detection
- Applied Research: DL-based TSS
- Overview
- Early Release
- International Recognition

- Applied Research: ML-based TSS
- Overview
- Traffic Scene Recognition
- Background Subtraction
- Daytime Vehicle Detection
- Nighttime Vehicle Detection
- Vietnamese License Plate Recognition
- Abandoned Vehicle Detection
Our newest achievements have been updated here !!
Research Statement
Research in our lab focuses on branches of computer vision. In the field, we are intrigued by visual functionalities that give rise to semantically meaningful interpretations of the visual world. In computer vision, we aspire to develop intelligent algorithms that perform important visual perception tasks such as object recognition, scene categorization, etc. Our curiosity leads us to study the underlying imaging learning mechanisms that enable the human visual system to perform high level visual tasks with amazing speed and efficiency.

Theoretical Research
Background Modelling and Foreground Detection
TensorMoG: Tensor-driven background modelling and foreground detection
Background subtraction is a powerful technique in the field of Computer Vision for extraction
of motion features known as foregrounds.
Among the many techniques published from the research community, statistical unsupervised
learning variants of the Gaussian Mixture Model are most widely used in practice.
The choice can be rationalized because the contexts of scenes in real time are so dynamic
that a supervised data-driven model (e.g. a deep learning model) currently cannot reliably
interpolate predictions on unseen data.
Therefore, this work proposes an unsupervised, parallelized, and tensor-based approach that
algorithmically models backgrounds of scenes, that can be used for segmentation of motion
attributes.
Conducted experiments suggest that the proposed model is not only efficient and effective,
but also highly integrable into a mobile surveillance system that utilize multi-processing
technologies such as GPU, TPU, etc.
Published research of GMM and its variants has showcased GMM's capability at background
modeling at the pixel level.
They accomplish their tasks via algorithmically maximizing the expectation (i.e. the EM
algorithm) of a multi-modular probability density function known as the Mixture of Gaussians.
Whilst online learning, the model simply selects from its components the background
constituents satisfying certain criteria.
Thus, GMM background models are universally capable of exhibiting rapid statistical
adaptation in terms of color space for capturing spatio-temporal scene dynamics,
thereby making them a commonly opted tool for many applications. Meanwhile, published
research of deep neural networks (DNNs) have also reasonably demonstrated their
effective generalization capabilities on background modeling, and foreground extraction.
These models employ the use of high-powered
multi-processing technologies in order to effectively learn on large-scale dataset to produce
high performance in accuracy. However, problems arise and challenge not
only practical usage of these background modeling frameworks, but also empirical studies into
them. Beside from the lack of transparency with the inner
workings of these DNNs models, and great computational expenses, they still cannot account
for all the contextually different scenarios of the real world.

On deployment, we tested using the same configurations on the aforementioned dataset on a CUDA-capable mobile board called Jetson Nano B01. The recorded speed is ~27fps on this device on image dimensions of 320 x 240, thereby concluding that the model can process in real-time. Due to the nature of its parallel processing, the proposed model is also able to process signals of multiple cameras at the same time via tensor concatenation. With this feature along its accuracy and impressive speed, the proposed model is capable of providing a major advantage for mobile traffic surveillance systems.
HVR: Background subtraction with high variation removal
Background subtraction has been a fundamental task in video analytics and smart surveillance
applications. In the
field of background subtraction, Gaussian mixture model is a canonical model for many other
methods. However, the unconscious
learning of this model often leads to erroneous motion detection under high variation scenes.
This article proposes a new method
that incorporates entropy estimation and a removal framework into the Gaussian mixture model
to improve the performance
of background subtraction. Firstly, entropy information is computed for each pixel of a frame
to classify frames into silent or high
variation categories. Secondly, the removal framework is used to determine which frames from
the background subtraction process
are updated. The proposed method produces precise results with fast execution time, which are
two critical factors in surveillance
systems for more advanced tasks. We used two publicly available test sequences from the 2014
Change Detection and Scene
background modeling data sets and internally collected data sets of scenes with dense
traffic.
In practice, novel algorithms have a compromise between accuracy and speed performance. Some
methods performed many sophisticated operations to obtain acceptable results that result in
consuming high computing resources, which is unsuitable to be deployed
for any practical TSS that require background subtraction. Among
proposed methods, GMM is the most widely used method in TSS
because of its capability to tackle dynamic scenes and noise. However, it can generate
overlapping updates in case of high-variation
motions where other incorrect models replace the essential background models.

Input image

Extracted foreground
In this work, the authors proposed a method which not only
increase the precision in segmentation but also reduce the processing
time. We define two types of the image frame in input sequences:
silent frames which are reliable to update background model, and
high variation frames, which contain a high degree of motion. The
best approach to reduce false update of background model and a
wasteful process is to remove high variation frames from input data.
We present a method based on entropy calculation, which determines
the complexity of the per-pixel model and a high variation removal
method to manage the updating of the background model.
Occlusion Detection in Image Segmentation
Occlusions detection is a famous problem in optical flow in particular
and the field of image processing in general. Moreover, most problems in
video processing such as object tracking, 3D object reconstruction, motion
blurring, and unexpected objects removing are difficult problems to optimize due
to the lack of the motion vector’s information at the pixels in the occlusion regions
between two consecutive frames.

One of the ways to improve the quality of video processing applications
is to detect occlusion regions accurately. In reality, there are many methods are
used to detect occlusion regions. These methods can be divided into two main
groups: the computation of two PDEs (Partial Differential Equation) optical flow
problems and the combination of forward optical flow and image segmentation.

We also proposed a method
that can detect occlusion region by calculating only one partial differential equation
problem. It means that the estimation of optical flow procedure is only called once
and this does not use boundary detection method or the segmentation method.
Pre-processing Filters for Vehicle Detection
Shadow Removal for Vehicle Detection in Traffic Surveillance System
One of the barriers against building an effective traffic
surveillance system (TSS) is the existence of shadows. They
restrain the accuracy of object monitoring in two most prominent ways. Firstly, cast shadows
that lie beside conveyances
deforms vehicle shapes and leads to miscalculations of their
geometrical features. Secondly, shadows confuse a TSS as
they fill the inter-vehicle spaces, making it prone to mistaken
groupings of different vehicles. Therefore, a TSS in countries
such as Vietnam where it is almost always sunny especially
requires good shadow suppressions.
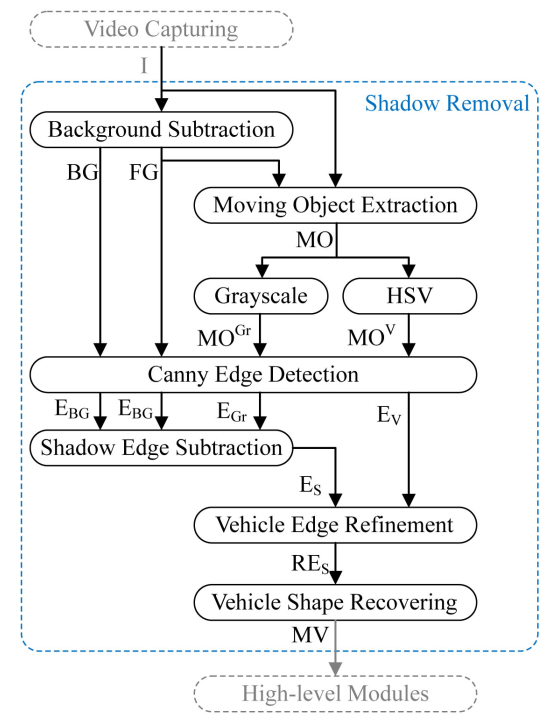
The proposed shadow removal algorithm is based on edge information from both
the input frame and the lightness component of the HSV color model that works
robustly in daytime traffic scenes. The advantages of our method are: 1) the algorithm
is designed as a filter, hence increasing the adaptability and performance; 2) the
algorithm is robust to a variety of shadow orientations, shapes, and appearances under
different lighting conditions; 3) the algorithm can precisely remove shadows from the
background. Experiments have been carried out to test the performance of our algorithm.
The results show that our algorithm performs better than previous methods. It can
produce satisfactory vehicle segments when shadows appear in both smooth and
textured backgrounds.

Experiments, which have been carried out to test the performance
of our algorithm, showed that our method comes with a good
compromise between shadow detection accuracy and shadow
discrimination accuracy rates by producing satisfactory vehicle
segments when shadows appear in both smooth and textured
backgrounds. In the end, our method still runs in real-time
speed either when processing a single or multiple traffic
sequences.
Reflection Detection and Removal for Vehicle Detection in Rainy Traffic Scenes
Reflection detection and removal have always played a
crucial role in traffic surveillance systems that are based
on computer vision techniques. In this work, we focus
on solving the problems of shadow in rainy conditions.
The reflections, post two
main problems. Firstly, in daytime condition, the cast
shadow is normally a uniform gray region. Meanwhile
in rainy conditions, the vehicle reflection consists of
a variety of colors. This greatly reduces the accuracy
of shadow detection algorithms which are solely based
on finding the intensity differences between the image
background and foreground. Secondly, headlights are
also reflected on the road which distort the length and
shape of vehicles. Since reflections also have the same
motion as the vehicles casting them, hence distort the
shapes, sizes, and colors of vehicles. Thus, it can cause
significant errors in vehicle detection and classification.
In this research, we propose a reflection detection and
removal algorithm that can work robustly in rainy conditions using data from actual traffic
surveillance video.
We also incorporate the
HSV color space mentioned in to our method. We
will combine information from both LAB color space
and HSV color space to detect the reflected areas. This
method can provide good results, and hence achieve
better accuracy when removing reflection but still maintain vehicles’ textures.
The reflection removal is performed by gradually scaling the intensity of reflected
areas to match with the average value of the best-fit
neighbor region. In the proposed method,
we use the meanshift algorithm to calculate the average
intensity value for each neighbor region and lighten
up the shadow parts according to it. Finally, we also
propose a simple technique to deal with headlights’
reflections. We first investigate the L channel to locate
the highest intensity pixels, which represent the source
of headlight and its reflection. Then the headlights with
the reflection that has soundable amount of displacement are grouped together.
After that we simply remove the bottom segment as it represents the reflection.

The proposed method is also designed to deal
with the cases of headlight reflection. By taking the
advantage of the intensity differences between headlights and their reflections, we can
easily detect and
segment them. We notice the fact that on wet road
surface reflections always reside under the headlights.
We simply remove reflections by rejecting the lower
segments. Several experiments have shown promising
results with detecting and removing vehicle reflections.
Applied Research: Deep-learning-based Traffic Monitoring System
Overview
Premise: Due to the rapid growth in the number of on-road vehicles, the past decade
has seen a dramatic increase in the demand for analyses of traffic capacity. Hence, automatic
estimation of traffic density has become pivotal in maintaining perpetual surveillance while
reducing human labour. Nevertheless, tackling traffic density estimation with cameras across
a plethora of scenarios, weather conditions, view perspectives and lighting is highly
complex. The domain of video sequences in the spatio-temporal color space is hardly
constrained in terms of context.
Our solutions: State-of-the-art technologies cohesively associates with a wide range
of research works that focus on extracting static and dynamic attributes regarding vehicles'
appearances and motion characteristics, including locations, shapes, sizes, categories,
trajectories, paths of movement, and time-series records of motion within the observational
views of monitoring cameras. In dealing with the estimation of vehicle counts in a
path-based, type-specific manner across a hardly constrained domain, we formulate our
solution by following a Deep-Learning-based approach.
Early Release
In the early stage of our research, we proposed a multi-contextual framework of vehicle
counting to present in
Ho Chi Minh City Artificial Intelligence Application
Challenge 2020.
The theme of the AI-Challenge 2020 contest is "Artificial Intelligence with Smart Traffic".
In this contest, the contest team will count the number of vehicles for each vehicle moving
in different directions in the video recorded from traffic cameras in Ho Chi Minh City.
This problem serves to analyze the volume of vehicles on the roads, thereby supporting
the proposal and design of solutions to reduce traffic congestion.
Aiming at practical solutions that can be applied in practice, the final ranking results
of the competing teams are evaluated on both criteria: accuracy (results of counting the
number of vehicles each type) and efficiency (algorithm execution time).
Requirements: Due to the high complexity of the data domain, the required
computational expenses were inevitable high. Our first
solution was proposed for inference using high-end desktops of at least a GPU of GeFORCE
1080Ti.
Contest regulations:
The contestants will develop an algorithm to count the number of vehicles of four types of
vehicles:
-
Type 1: 2-wheel vehicle such as bicycle, motorbike
-
Type 2: 4-7 seat car such as car, taxi, pickup ...
-
Type 3: car with over 7 seats such as bus, bus
-
Type 4: truck, container, fire truck
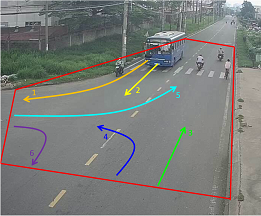
Each traffic video is recorded at a specific traffic camera. In each traffic video, the organizers will define an observation area (called Region-of-Interest , abbreviated as ROI) and the direction of movement (called Motion-of-Interest, abbreviated as MOI):
-
Field of view (ROI) is represented as a polygon, limiting the space to focus on the observation and processing to detect traffic.
-
Direction of Movement (MOI) helps identify lanes moving in different specific directions in the video.
In the illustration image below, the field of view (ROI) is defined as a polygon with a red
border.
There are 5 directions of movement (MOI), shown as 5 arrows.
This is our early-released version.
The solution won Second
Prize through
the evaluation on the private test data set of
Ho Chi Minh City Artificial Intelligence Application
Challenge 2020.
This work was directed by Dr. Synh Viet-Uyen Ha and was implemented by
Mr. Nhat Minh Chung (lead),
Mr. Hung Ngoc Phan,
Mr. Khoi Dinh Ngo,
Mr. Minh-Thong Duy Nguyen, and
Mr. Nhan Tam Dang.
We propose the methodology with four main modules:

-
Vehicle Detection and Classification;
-
Vehicle Tracking;
-
Determine the motion direction and the moving area of the vehicle;
-
Vehicle counting
A sequence of consecutive input images extracted from the camera is processed through the
Vehicle Detection and Classification Module.
Our team of contestants uses a deep learning model that has been trained on images that are
tagged and randomly extracted from the hand-labelled data.
After detecting and classifying the object, we will omit the objects that are outside of the
Motion-of-interest (MOI) field of view (i.e., an area different
from the Region-of-interest (ROI) we construct to suppress the jamming directions).
For the tracking module we use is built on the concept of the Simple Online and Realtime
Tracking (SORT) methodology.
Objects will be matched against each other based on three conditions.
The objects are instantiated if the match is not successful. Conversely, the objects will be
kept alive until they no longer exist in the processing field.
We, then, determine the travel direction and travel area of the vehicle.
Finally, when vehicles move out of the field of view, we will execute the counter for the
respective vehicle type and the MOI movement direction
that was previously determined. At the same time, results of the counter are exported to the
result file for further storage.
International Recognition
The 6th NVIDIA AI CITY CHALLENGE (2022)
Challenge Track 2: Tracked-Vehicle Retrieval by Natural Language Descriptions
Vehicle retrieval is an important asset for the development of intelligent traffic systems in smart cities. In particular, being able to query for vehicles of interest from the pool of large databases is a powerful capability, as it brings along a wide array of useful applications in urban planning, traffic engineering, and security maintenance. While image-based vehicle retrieval systems have been the more prevalent type of approach, text-based vehicle retrieval systems have received noticeably increased attention in research. Unlike image-based retrieval systems which require at least an image of the target of interest, text-based ones can leverage easily obtainable natural descriptions of that target. In comparison with image queries, while text queries are arguably less effective in terms of describing fine-grained appearances, they are more intuitive, user-friendly and can easily provide for more layers of descriptions such as shape, color, position, and relativity to another target.
Therefore, to address the difficulties of this Track, we focus on developing a robust natural language-based vehicle retrieval system to mainly resolve the domain bias problem due to unseen scenarios and multi-view multi-camera vehicle tracks with following contributions:
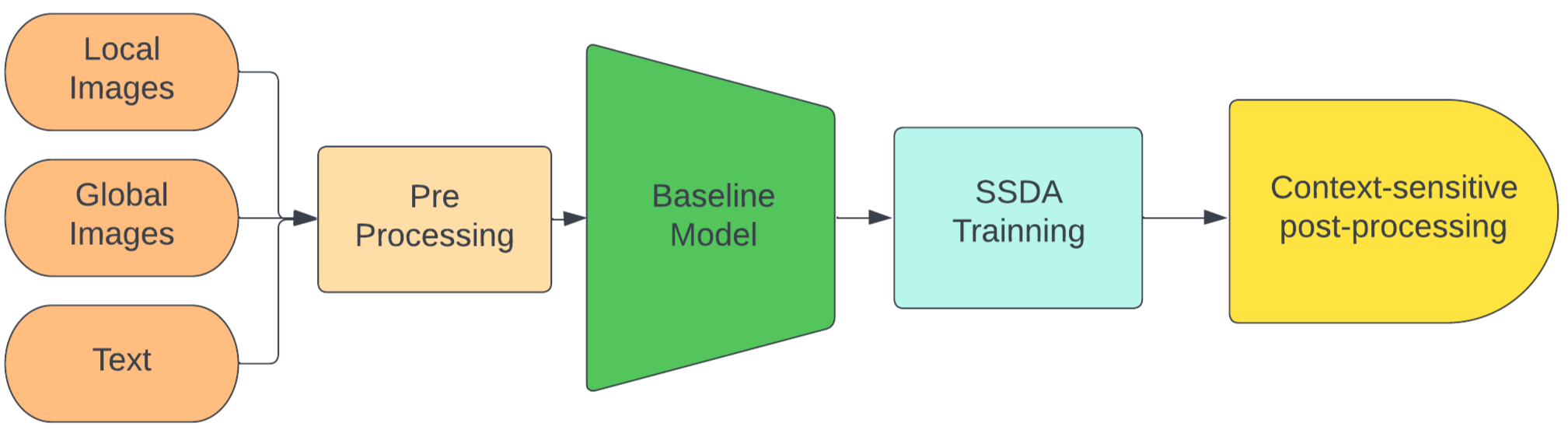
-
Efficient pre-processing method: Maximizing the amount of knowledge the model can learn and generalize, hence leveraging for the new domain adaptive training method.
-
Robust semi-supervised domain adaptive training approach: Addressing the domain bias between the training set and test set for the text-image retrieval model by enforcing the retrieval model to adapt new knowledge from the test set domain.
-
Context-sensitive post-processing method: Tackling the difference between appearance of different scenarios and multiple camera types and angles lead to wrong retrieval results.
Our proposed approach for retrieval traffic targets from natural descriptions includes a system sequence of 2 primary modules (Retrieval System (Deep Learning-Driven), Analyzing & Pruning wrong events System (Heuristic-Driven)).
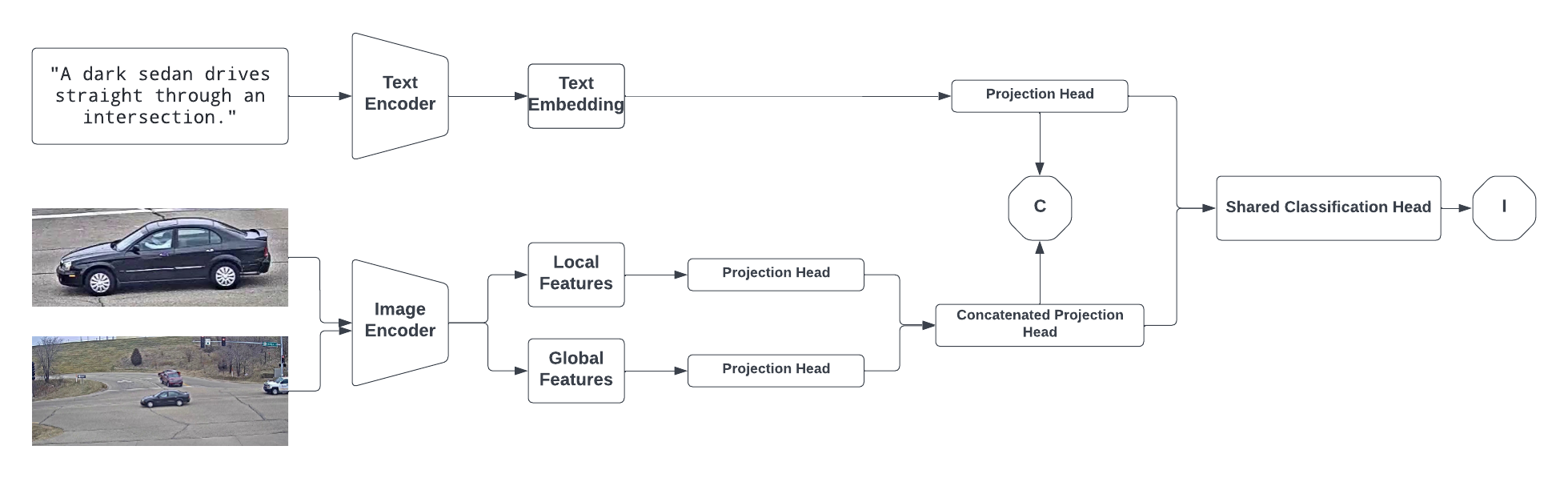
Domain-Adaptive Baseline Model::
The baseline model has a big impact on the overall result, therefore selecting pre-trained models with robust visual and text representations is crucial. Thus, our baseline model consists of 3 main components: backbone, head, and objective losses. We propose a SSDA (Semi-Supervised Domain Adaptative) training scheme for CLIP to enforce domain adaptation, overall in 2 stages.
-
We use famous CLIP from openAI as our main backbone to leverage its powerful knowledge in creating robust representation for both textual and visual data.
-
We consider adopting the dual-stream input to incorporate the information from both type of data into the model. Additionally, Each representation for text and dual-stream image is then fed into independent projection heads with the intention to map each domain space into the space of contrastive representation learning where contrastive losses are applied.
-
we adopt the symmetric Cross-Entropy (InfoNCE) Loss due to its ability to alleviate the model to learn multi-modal embedding space by jointly training visual and text embedding to maximize the similarity between positive pairs and minimize the rest negative pairs simultaneously.
The design of the proposed baseline is not only robust and effective for a noramal retrieval task but also capable of incoporate different domain knowleage from further domain adaptation technique.
Achievement::

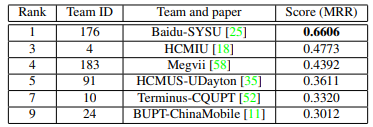
-
With the accuracy of ~0.47, our team achieved a very competitive final score of MRR (Mean Reciprocal Rank) = 0.4773 as a runner-up, which is a solid top-2 solution only lower than the 1st team from Baidu - China
-
Our ranking remarked a higher score than other teams from China, Korea, Vietnam and the US.
Our solution has been internationally recognized in a research paper published and presented in CVPR 2022, which is a Top-Ranking A* conference:
Challenge Track 1: City-Scale Multi-Camera Vehicle Tracking
The 5th NVIDIA AI CITY CHALLENGE (2021)
Challenge Track 1: Multi-Class Multi-Movement Vehicle Counting Using IoT Devices
In real-world applications, taking into account scaling-up strategies of practical implementations, the vehicle counting task needs to be carried out on computationally limited platforms at real-time execution efficiency. As a result, mimicking in-road hardware sensor-based counting on IoT devices necessitates that vision solution settings well utilize hardware resources in terms of computations and memory complexities.
Hence, we redesigned our previous solution to accomodate practical requirements:

-
Effectiveness: Utilizing the data-driven framework of Deep Learning and supporting algorithms on the complex domain, our approach can perform with high accuracy across a number of scenarios.
-
Efficiency: Satisfying the online, real-time demand of traffic surveillance systems, our approach combines light-weighted components with simple heuristics to function at high speed on IoT devices.
-
Scalability: The solution has been much more streamlined, and thus much more deployable than its early-release version. It is capable of online, real-time performance on an NVIDIA Jetson Xavier NX device.
Our proposed approach for retrieval traffic behaviors includes a system sequence of 3 primary modules (Detection, Tracking, Counting) in a multi-threaded manner, where each is responsible for a specific task: 1) vehicle detection, 2) vehicle tracking, and 3) path-specific vehicle counting.
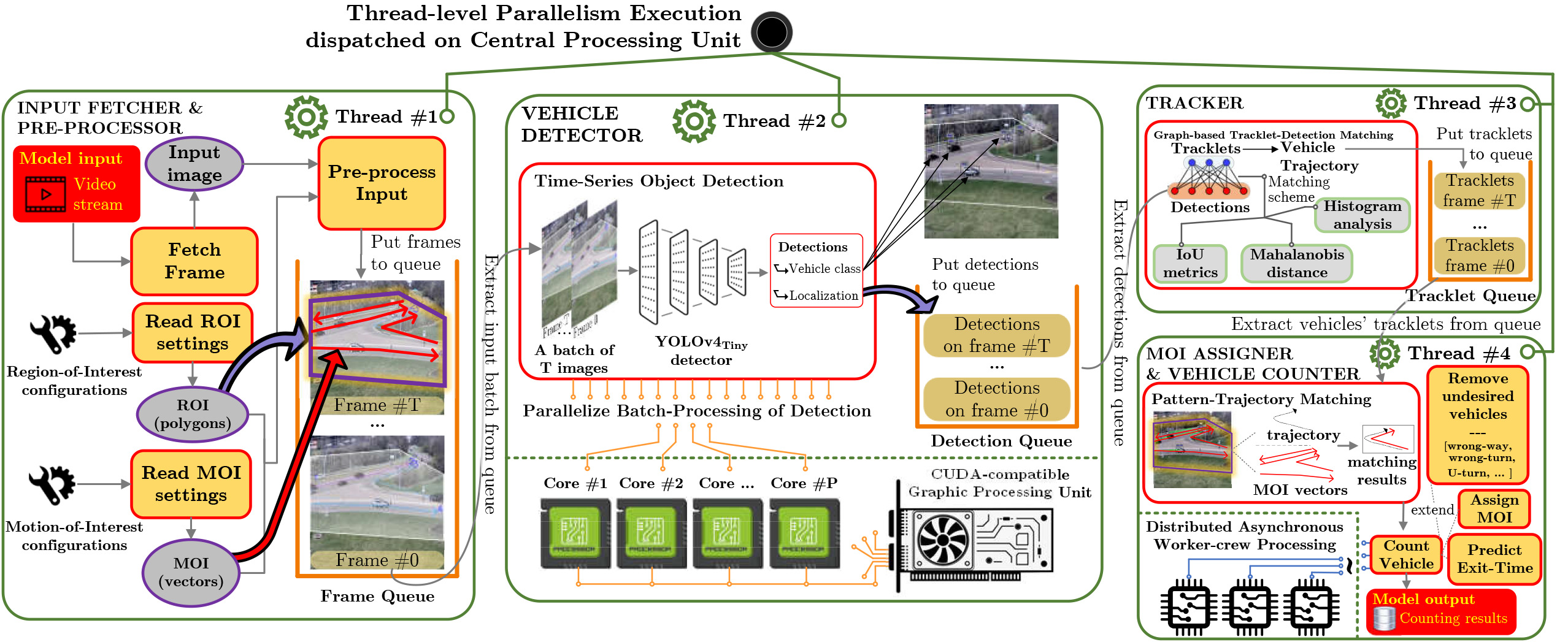
Thread-level parallelism::
-
We receive a traffic video containing multiple vehicles of interest and preprocess it along with predefined ROIs (regions-of-interest) and MOIs (motions-of-interest) settings.
-
We produce a list of detected vehicles via performing batch object detection recognize vehicles in view; then we perform our proposed three-fold matching scheme for tracking vehicles’ trajectories.
-
We record vehicles of interest that have exitted the field of observation based on MOIs configurations that represent real-life paths.
The design of the proposed solution is not only robust and effective for a wide array of scenarios but also capable of making efficient use of available computing resources.
Online Directional Multi-Vehicle Tracking::
![]()
A tracking algorithm is one of our major contributions in the proposed system. It is formulated around a three-fold data association scheme supported by inter-frame predictions of vehicle positions. Specifically, by leveraging vehicle detections estimated by the object detector, our algorithm employs the Kalman Filter (KF) to predict vehicles’ positional displacements throughout a scene, thereby enabling effective data association of each vehicle using the Hungarian Matching algorithm on account of a target’s bounding box geometry, its directional position with respect to the vehicle’s Kalman Filter state, and its RGB color histogram.
Achievement::

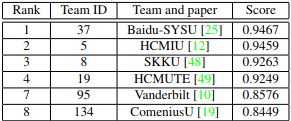
-
With the speed of ~50fps on Jetson NX and an accuracy of ~0.94, our team achieved a very competitive final score of S1 = 0.9459 as a runner-up, which is only 0.0008 lower than that of the top team from Baidu - China.
-
Our ranking remarked a higher score than other teams from Korea, Vietnam and the US.
Our solution has been internationally recognized in a research paper published and presented in CVPR 2021, which is a Top-Ranking A* conference:
Applied Research: Machine-learning-based Traffic Surveillance System
Overview
Smart traffic surveillance system is a system through CCTV to extract necessary information from which to assist users in regulating and managing traffic conditions at monitoring points. The intelligent transport system is a large system consisting of three main parts:
-
Image signal processing center: In this module, the system receives video signals from CCTV installed at monitoring points on the road. Next, the servers analyze the objects from the image to extract the necessary information. Then, the system gathers the data and prepare for the simulation step. This is our focus research in the field of computer vision.
-
Simulation center: This module analyzes based on the information provided by the camera signal processing servers and simulates the traffic situation on the calculation models. Thereby, the system evaluates and makes predictions about congestion and traffic jams. Accordingly, the system offers optimal traffic light adjustment solutions to reasonably coordinate traffic volume at intersections.
-
Traffic operating center: The module plays the role of applying and implementing traffic light solutions to the real environment.
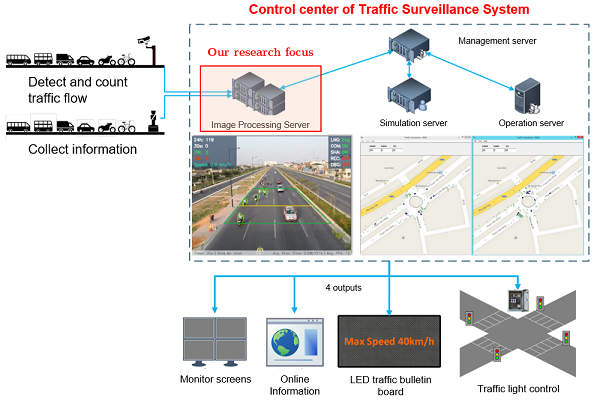 The primary proposal is a vision-based traffic surveillance system that has been
implemented since 2014 on Vo Van Kiet avenue, which was directed by Dr. Synh Viet-Uyen
Ha
Our proposed work has capability of contextual adaptability including daytime (overcast, shadow,
rainy) and nighttime.
The team leader of this project is Mr. Long Hoang Pham (M.Eng.).
Our work has been conducted by both current members and previous alumni.
The primary proposal is a vision-based traffic surveillance system that has been
implemented since 2014 on Vo Van Kiet avenue, which was directed by Dr. Synh Viet-Uyen
Ha
Our proposed work has capability of contextual adaptability including daytime (overcast, shadow,
rainy) and nighttime.
The team leader of this project is Mr. Long Hoang Pham (M.Eng.).
Our work has been conducted by both current members and previous alumni.In recent years, there has been an increasing interest in the area of traffic surveillance system (TSS), especially in Vietnam as well as other developing countries. TSSs are mainly used to provide supports for traffic management systems in urban areas where the road infrastructures are stressed by the steadily increasing in traffic flow levels. The resulting high levels of congestion and delay can cause high economic and environmental costs. The main goal of TSS is to gain an understanding of traffic situations through extracting information (counts, speed, vehicle type, and density) by analyzing video (recorded or real-time) from surveillance cameras.
So far most studies have only been carried out in developed countries where traffic infrastructures are built around automobiles, but in Vietnam, motorbikes are dominant (around 39 million by the end of 2013). Hence, Commercial-Off-The-Shelf TSSs have failed to cope with the chaotic traffic caused by 2-wheeled motorized vehicles to provide needed information. Some earlier works have proposed methods to detect and classify moving vehicles in urban areas. However, these methods are limited to ideal conditions (i.e., early morning or cloudy day without the appearance of shadows), and they can only classify vehicles into two types: 2-wheeled and 4-wheeled.

Therefore, this work aims to improve the algorithms for vehicle detection, tracking,
and classification to work robustly in daytime scenes. Also, the proposed algorithm will
classify vehicles into three classes: light (motorbikes, bikes, and tricycles), medium
(cars, sedans, and SUVs), and heavy vehicle (trucks and buses). Moreover, the proposed
algorithm will be integrated with other modules to create a unified TSS system as
described in figure above.
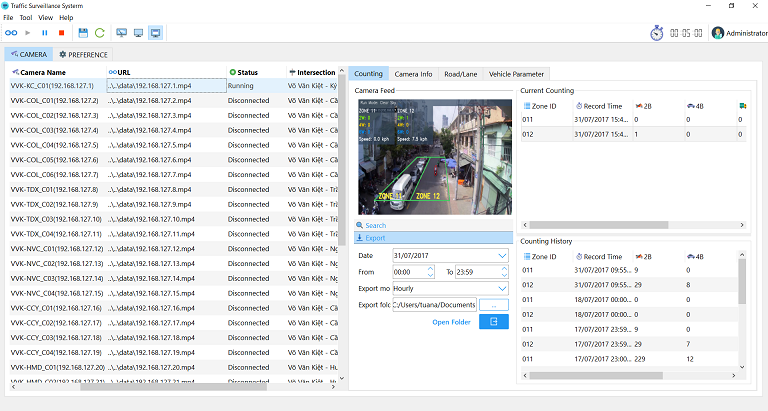
We implemented a friendly graphical user interface to perform advanced tasks at high level including user management, camera organizing, periodical traffic data exporting, result displaying, etc.
Traffic scene recognition
In proposed framework of TSS, we provide different solutions for each context of traffic
scenes.
First, traffic scenes are categorized into a variety of conditions in which appropriate
methods of vehicle detection and classification
as well as advanced tasks are perform.
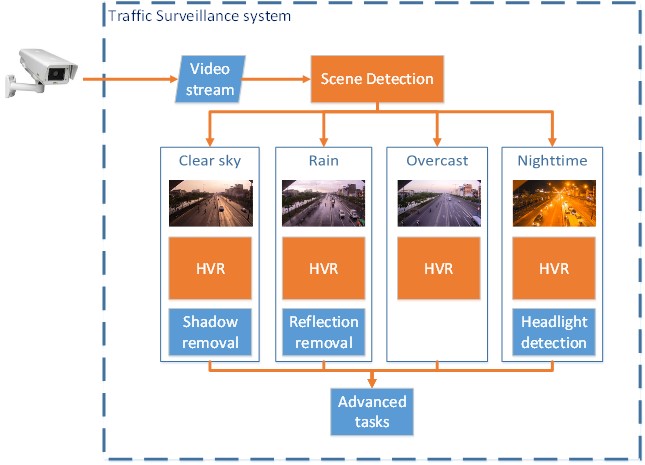
We introduced an approach of traffic scene classification using neural networks.
From the input frame, there are two observations in the camera field-of-view (FOV) containing
the sky part and the road.
For dual sampling regions, consisting of an observation zone and a sky region is applied.
It is a common practice to get the sky region using watershed segmentation in combination
with the horizon line.
The method acquires the region cover most of the sky, because it gets whole characteristic of
the sky, and avoids some small
changes which would make the wrong detection. For example, the raincloud which does not cover
the sun would alter the detection if the sky region is on the cloud.
However, the observation zone authors just cover a part of the road, which is the area the
TSS uses for vehicle detection.
The color intensity of sky is different in the daytime and nighttime, their histogram changes
dramatically from high in the nighttime to low in the nighttime.
From the daily repeat fluctuation, the TSS could accurately recognize the change in
scene.

Additionally, authors use the observation zone on the road to identify the condition of the road. For more detail, the shadow detection is the technique to distinguish the overcast scene from the others. Furthermore, the proposed method uses the features from the observation zone and the sky region to determine the two-left scene, the rain, and the clear sky. There are many confused features between the clear sky and the rain. For example, after the rain, the sky is clear, and the road is wet, which make the reflection of the vehicle; Therefore, in this case, the scene is the rain. Later, when the road is dry; the scene is the clear sky. This work was implemented by Mr. Duong Nguyen-Ngoc Tran.
Background Subtraction
In crowded cities, traffic congestion is a serious challenge to any existing modeling
algorithm.
In this context, slow-moving vehicles or high-density pedestrians can cause chaos and damage.
As can be seen in Figure 10, many motorcycles, cars, pedestrians go along the unordered road.
Vehicles can stop waiting for pedestrians to move slowly so that congestion can occur.
Furthermore, the impact of outdoor lighting also affects the background effect.
In general, the input frames affected by such effects are known as framing (or images)
disorders and must be eliminated.
In practice, novel algorithms have a compromise between accuracy and speed performance.
Some methods performed many sophisticated operations to obtain acceptable results that result
in consuming high computing resources,
which becomes a dilemma for any practical system using background subtraction, especially,
TSSs which have to deal with outdoor effects
and resource management. Among proposed methods, GMM is the most widely used method in TSS
because of its capability to tackle dynamic scenes, noise.
However, it can overlap update in case of high-variation motions where other incorrect models
replace the essential background models.

Input image

Extracted foreground

Modelled background
In the work, authors proposed a method which solves the dilemma in practice mentioned above,
which not only increase the precision in segmentation but also reduce the time-consuming for
processing.
The authors define two types of the image frame in input sequences: silent frames which are
reliable to update background model, and high variation frames contain a high density of
motion.
The best approach to reduce false update of background model and a wasteful process is to
remove high variation frames from input data.
Approaching to this solution, the authors present a method based on entropy estimation which
determines the complexity of the per-pixel model and a high variation removal method to
manage the update of background model.
This work was implemented by Mr. Duong Nguyen-Ngoc Tran and Dr. Tien
Phuoc Nguyen.
Daytime Vehicle Detection
The proposed system follows the object-based approach for vehicle detection and tracking. In other words, it is essential to count each vehicle only once and extract certain measurement features. To ensure that two key considerations: camera mounting configuration and observation zone, are taken into account when implementing the vehicle detection algorithm.
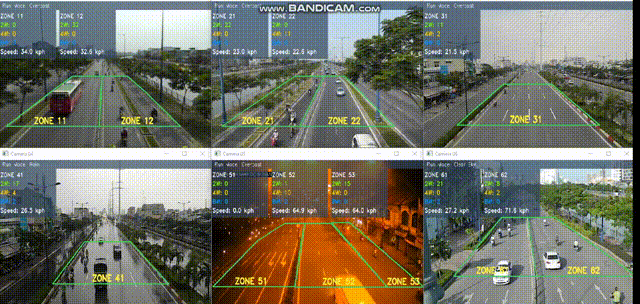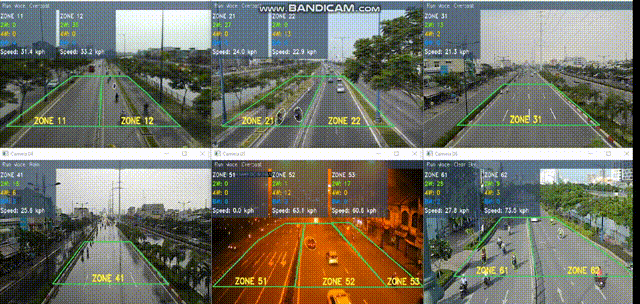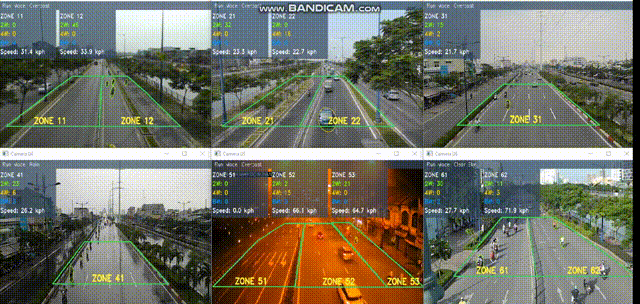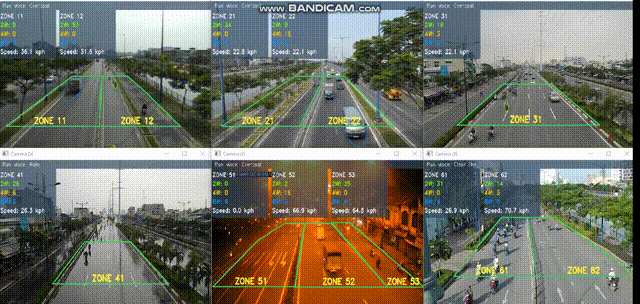
The proposed framework can work well under different outdoor conditions including
overcast, rainy, clear-sky, sunny, and crowded scenes with an average accuracy of 89% and a
real-time processing rate of 33.9 frame per second
on an unexceptional configuration of personal computer.
This work was implemented by
Mr. Long Hoang Pham (overcast, rainy, clear-sky, sunny scenes),
Mr. Nhan Thanh Pham (rainy scenes),
Mr. Hung Ngoc Phan (crowded scenes).
Nighttime Vehicle Detection
The past decade has seen increasingly rapid advances in the field of computer
vision which in turn has led to a renewed interest in traffic surveillance systems
(TSS). Vision-based traffic monitoring systems have the capability to provide
fast and reliable information that is necessary for a wide range of applications
such as traffic management and congestion mitigation. The main objective is to
detect interesting objects (moving vehicles, people, and so on.). Other targets
include classifying objects based on their features and appearance (shape, color,
texture, and area), counting and tracking vehicles (trajectory, motion), assessing
the traffic situation (congestion, accident). While later processes are dependent
on specific application requirements, the initial step of object detection must be
robust and application independent.


From the literature review, we propose an algorithm to detect and classify
vehicle in nighttime based on observations on real-world data. The novelty of
our work is that headlights are first validated and then paired using trajectory
tracing approach. Our algorithm consists of four steps. First, bright objects are
segmented using the luminance and color variation. Then, the candidate headlights
are detected and validated through the characteristics of headlight such as
area, centroid, rims, and shape. In the next step, we track and pair headlights by
calculating the area ratio, spatial information on common vertical and horizontal
of the headlight. Finally, vehicles are classified into two groups two-wheeled and
four-wheeled. Experiments have shown an effective nighttime vehicle detection
and tracking system for identifying and classifying moving vehicles for traffic
surveillance. This work was implemented by Mr. Tuan-Anh Vu.
Vietnamese license plate recognition
The goal of license plate location is the spacial detection of an image region
wherein the plate lies. Through license plate detection, which employs a coarse-to-fine
strategy, we aim to reduce the data amount that needs to be processed.

We have outlined a solution that utilizes a combination of binary
image processing methods (mathematically morphology operations, binary
algorithms), color processing methods (color model transformation, histogram
projection profile) and classifiers. The outlined solution provides a noteworthy
real-time solution to automatically detect license plates in the given video dataset taken
from Trung Luong Road despite the considerable poor image quality, due to low video
quality and the changing outdoor weather. The algorithm processes on average 36
frames per second and can detect plates correctly 88.9% of the time while it can detect
plate characters with 88.1% accuracy. This work was implemented by Mr. Duong
Nguyen-Ngoc Tran
and Ms. Minh-Thuy Thi Pham.
Abandoned Vehicle Detection
Abandoned Object Detection plays a significant role in many surveillance systems to
extract important information such as abandoned luggage, parking vehicles (counting,
warning).
In this topic, stopped object detection has emerged as an influential field of study. So far,
there has
been a considerable amount of research to accommodate this subject. However, these studies
have
only been detecting stopped objects for a very short period of time and require offline
processing.
Detecting stopped objects in crowded scenes has become a difficult task because of
high-frequency
occlusion between moving persons or vehicles to any considering stopped objects. This issue
is
even more challenging without an initial empty background where removed objects are detected
as stopped objects causing wrong and miss detections. This work presents a method to improve
stopped objects occlusion problems, increase the accuracy of stopped object detection and
maintain stopped objects almost permanently for online processing.
One applications of this method is to
measure the waiting/congested queue of traffic flow (left).
Also, we use this approach to detect vehicles that stop or park
in contravention of regulations (right).


We extended this method to detect neglected baggage or dropped luggage..


The result outperforms other methods even
in small size detection, occlusion of moving and static objects, background maintenance, wind
jittering. Hence, it shows that the algorithm is very accurate and more if an approximately
good
background is given. If no background is available, the model can be trained for a long
period of
time to retrieve the good background without static objects before further processing or can
be
applied directly with human interaction to achieve the required background. The selective
background model can also be modified in module to further improve the classification method
of
“abandoned and removed” objects. This work was implemented by Mr. Nhat-Hoang Tran
Nguyen.